|
|

|

|
| e-Pub |
Section: New Results
Unsupervised Activity Learning and Recognition
Participants : Serhan Cosar, Salma Zouaoui-Elloumi, François Brémond.
keywords: Unsupervised activity learning, hierarchical activity models, monitoring older people activities
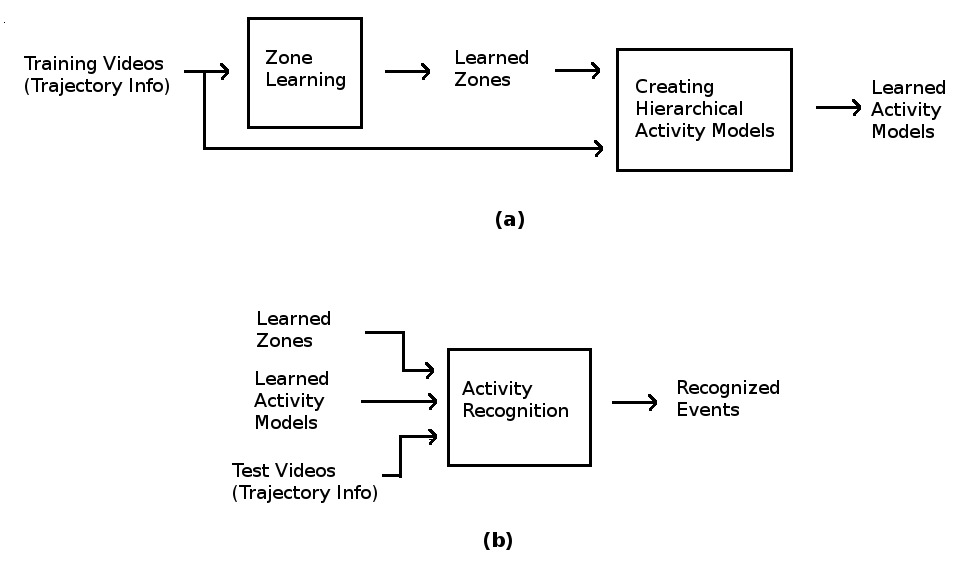
The aim of this work is to monitor older people activities at hospital or at home environment in an unsupervised manner. We have extended the work in [81] that was initially based on user interface to label activities and proposed a new strongly unsupervised framework. It enables the discovery, modeling, and recognition of activities without user interaction. One advantage of this approach is that the framework learns individual behavioral patterns in unstructured scenes without restraining people to act based on a manually pre-defined model. The Figure 40 -(a) presents the off-line learning steps of this framework. It takes as input a set of videos pre-processed to obtain trajectory information of people in the scene. Using the trajectory information (global position and pixel tracklets of body parts) of each person, zones of interest, where the person performs an activity, are learned. As in [81] , we obtain three levels of zones using -means clustering for different values. The obtained zones are used to create different levels of events from the coarser to the finer ones. Based on the three levels of events, a hierarchical model of activities is learned to represent each action (Figure 40 -(a). For each new video, an on-line recognition process is performed by using the previously learned zones and models of activities (Figure 40 -(b)).
|
We have evaluated the performance of the unsupervised algorithm for RGB-D and 2D camera using 8 videos and 10 videos, respectively. Half of the videos are used for learning zones and models of activities. Videos are recorded in CHU Nice hospital while older people are visiting their doctors and include the following actions: “talking on the phone”, “preparing drugs”, “sitting at the table”, “preparing tea”, “looking at the bus map”, “watching TV” and “paying bill”. The trajectory information for 2D camera is obtained using the method in [81] . For RGB-D camera, we have used the person detection algorithm in [79] and tracking algorithm in [33] . The results obtained for both cameras are presented in Table 6 and Table 7 , respectively. We have used the following metrics to evaluate the framework: TP: True positive, FP: False positive, FN: False Negative, Sensitivity and Precision. According to the trajectory information, sometimes -means clustering produces zones that are actually union of more than one zones. For such cases, we have combined the actions and presented as one single action.
| Actions | Instances | TP | FP | FN | Sensitivity(%) | Precision (%) |
| Paying bill | 13 | 5 | 0 | 8 | 38.46 | 100 |
| Preparing drugs | 7 | 5 | 5 | 2 | 71.42 | 50 |
| Looking at bus map+Watching TV | 21 | 6 | 3 | 15 | 28.57 | 66.66 |
| Sitting at the table | 18 | 6 | 10 | 12 | 33.33 | 37.5 |
| Talking on the phone | 23 | 17 | 1 | 6 | 73.91 | 94.44 |
| Preparing tea | 23 | 11 | 3 | 12 | 47.82 | 78.57 |
| Actions | Instances | TP | FP | FN | Sensitivity(%) | Precision (%) |
| Paying bill + Watching TV | 13 | 12 | 8 | 1 | 92.3 | 60 |
| Preparing drugs | 5 | 5 | 0 | 0 | 100 | 100 |
| Looking at bus map | 9 | 9 | 10 | 0 | 100 | 47.36 |
| Sitting at the table | 8 | 4 | 34 | 4 | 50 | 10.52 |
| Talking on the phone | 14 | 13 | 1 | 1 | 92.85 | 92.85 |
| Preparing tea | 16 | 9 | 5 | 7 | 56.25 | 64.28 |
As it can be seen in the tables, we obtain higher recognition rates by using the information coming from RGB-D camera.
Table 6 shows that for “talking on the phone” and “preparing drugs” actions occurring in two distant zones, using 2D camera gives high recognition rates (higher than 70 %). However, the actions “looking at bus map”, “watching TV” and “sitting at the table” are misclassified (low TP and high FP). Since the zones of these actions are very close to each other, the actions occurring in the borders are not well recognized. The reason of high FN is due to the problems in detection and tracking with 2D video cameras. The process of trajectory extraction described in [81] sometimes fails to track people. Because of the inadequate trajectory information, we have many FNs. Therefore, a better detection can considerably enhance the recognized actions.
By using the information coming from RGB-D camera, except for “sitting at the table” and “preparing tea” actions, we achieve high level of recognition rates (Table 7 ). However, similar to 2D camera, the recognition of “sitting at the table”, “paying bill” and “watching TV” actions fails because the learned zones in the scene are very close to each other. Hence, we have many false positives (FP) and false negatives (FN) for “sitting at the table” and “preparing tea” actions.
In the light of the preliminary experimental results, we can say that this unsupervised algorithm has a potential to be used for automated learning of behavioral patterns in unstructured scenes, for instance in home care environment for monitoring older people. Since the current framework does not require the user interaction to label activities, an evaluation process on big datasets will be easily performed. The proposed framework gives one action at each zone in an unsupervised way. We are currently focusing on refining the actions for each zone by using the pixel tracklets of the person's body parts. This will be achieved by performing clustering among activity models. As an example, the action of “sitting at the table” will be decomposed to “reading newspaper while sitting at the table” and “distributing cards while sitting at the table”.